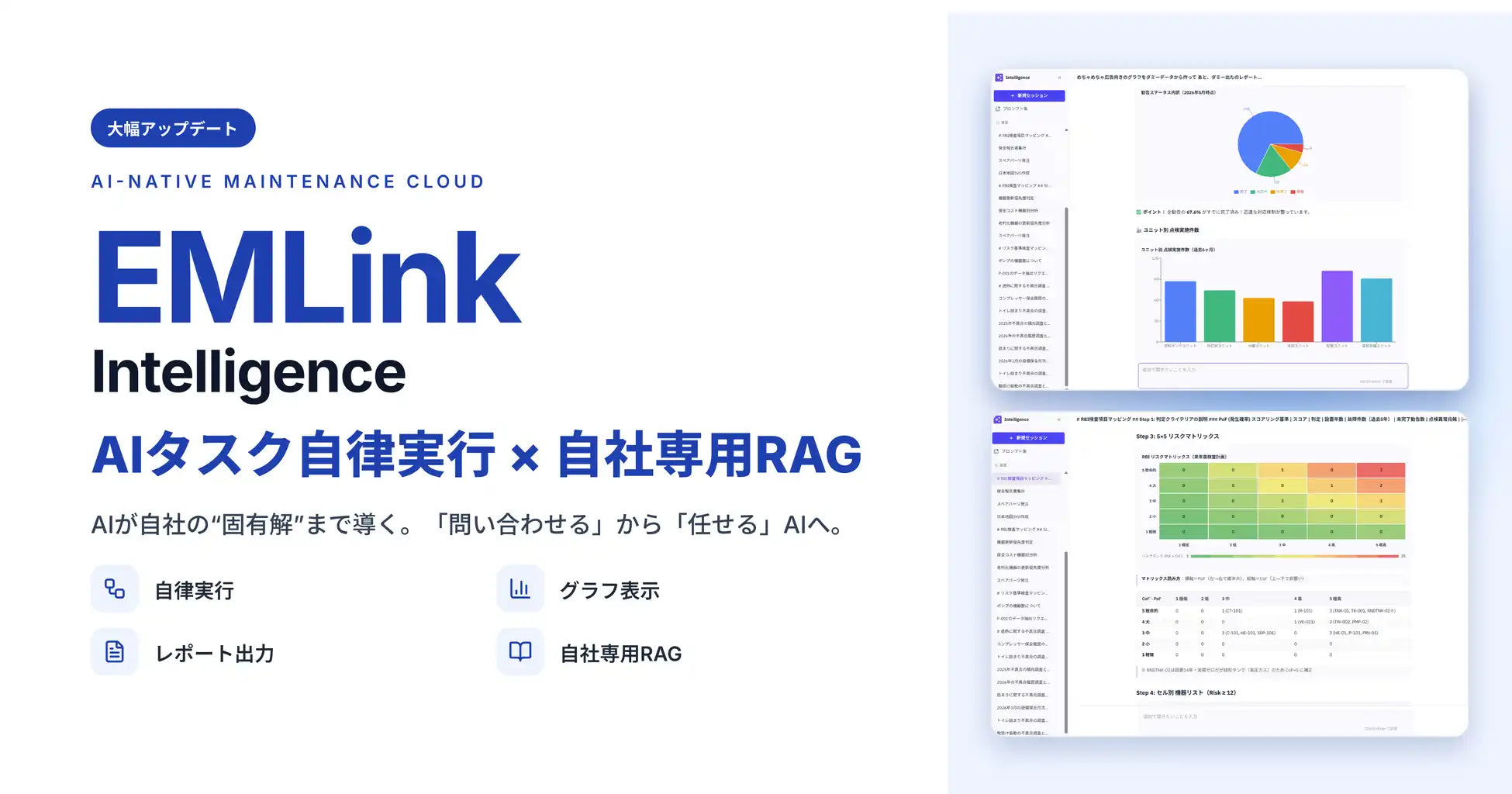
本記事ではGoogle ColabでStable Diffusionを使い、AI漫画で使うキャラクターを作る方法について解説します。
本記事を読むことで同一の被写体を作る方法や、さまざまなポーズをとる上で大切なことについて理解できるのが特徴。AIで漫画を描きたい人にとって欠かせない内容と言えるでしょう。
また、余談ですが筆者はAI漫画を作る際、けいすけさん(@kei31)というAI漫画家を参考にしています。
結構できてきた!
— けいすけ / AIマンガ家 (@kei31) September 15, 2024
インディーズマンガのガイドブック pic.twitter.com/XrsK7wHAue
AI漫画の作り方に関するKindle本も出しているので、気になる方は本記事と併せて参考にすることがおすすめです。
では本題へ移ります。
Stable Diffusionでオリジナルのキャラを作るための概要
Stable diffusionでAI画像を作るうえで、押さえておくポイントは下記の通りです。
- AIモデルはAnimagine XLを使用
- 1回で同じ画像は出ない
- AIモデルの特徴に逆らわない
画像生成AIにおけるAIモデルとは、特定のテイストに特化して開発・事前学習されたプログラムのことです。
今回はアニメ風の画像に特化したAIモデルである「Animagine XL」をStable diffusionへインストールして使用します。
AIモデル「Animagine XL」を使用
Animagine XLはStable Diffusionを基に開発されたAIモデルで、特にアニメ風の画像生成に優れています。
Danbooruタグを利用し、高精細なアニメキャラクターや関連要素を描写できるのが特徴。手の描写や複雑なポーズの再現においても優れており、アニメファンやクリエイターにとって、簡単に高品質なアニメ画像を生成するための便利なAIモデルです。
1回で同じ画像は出ない
Animagine XLを使用して画像を生成する際、同じプロンプトを入力しても毎回異なる画像が生成されます。これはStable Diffusionのアルゴリズムがランダム性を含んでいるためで、生成結果に多様性が生まれることが理由です。
そのためオリジナルキャラクターで求めるポーズの画像を出すには、同じプロンプトを何度も実行することが必要です。
画像生成AIの外部サービスだと1枚の画像を作るまでに時間がかかったり、制限が設けられいたりします。しかしGoogle ColabでStable DiffusionのAPIを使うことで、プラットフォームの制約を受けずに高速かつ複数の画像を生成できるのです。
AIモデルの特徴に逆らわない
モデルごとに学習データが異なるように、Animagine XLで学習しているアニメや漫画のデータに偏りがあり、一定のテイストに落ち着くのが特徴です。
そこにプロンプトで細かく指定することで、同じキャラクターを生成しやすくしています。そのため、プロンプトを用いることで求める全ての画像を作れるわけではありません。
たとえばAnimagine XLを使ってみて感じたことなのですが、このAIモデルは男性の被写体を作ることが苦手なようです。男性を指定しても女性のような顔立ちの画像になったり、丸みを帯びた体になることが多数ありました。
逆に男性の被写体を多く学習したAIモデルを使うと、男性の画像を作ることは得意ですが女性の画像を作るのに向いていないこともあります。
このように利用するAIモデルごとに向き不向きがあるので、それに合わせて漫画で使う画像を作ることが最適です。
Stable Diffusionでオリジナルキャラクターを作るコツ
Stable Diffusionでオリジナルキャラクターを作るコツ
- 単語をコンマ区切りで記載する
- 作りたい画像の特徴をできるだけ細かく指定する
- ネガティブプロンプトを活用する
各内容について詳しく解説します。
単語をコンマ区切りで記載する
Stable Diffusionでプロンプトを入力する際、キーワードをコンマで区切って記載することでモデルが各要素を明確に認識しやすくなるのが特徴です。また、単語は英語で書く方がモデルが理解しやすく、より正確な結果を得られる傾向があります。
たとえば「girl, red dress, forest, smiling」と入力することで、それぞれの要素が独立して画像に反映されます。コンマ区切りは情報を整理し、モデルが意図を正確に理解するのに役立ちます。
作りたい画像の特徴をできるだけ細かく指定する
生成したいキャラクターやシーンの特徴を詳細に指定することで、モデルはより精密な画像を生成します。髪型、目の色、服装、表情、背景など、具体的な要素を盛り込みましょう。
たとえば「1girl, with long blonde hair, blue eyes, wearing a white dress, smiling, under a cherry blossom tree」のように詳細なプロンプトを指定することで、理想的なイメージを実現するのに効果的です。
ネガティブプロンプトを活用する
ネガティブプロンプトとは、生成したくない要素や避けたい特徴を指定する方法です。ネガティブプロンプトを活用することで不要な要素を排除し、望む画像に近づけることが可能です。
たとえば筆者が画像を作る際、下記のネガティブプロンプトを使用しています。
Worst Quality, Low Quality, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, normal quality,signature, watermark, username, blurry, multiple legs, multiple hands, incorrect limb and crotch, less than surrealism, fused fusion, long body, bad perspective, logo
日本語訳
最低品質, 低品質, 解剖学的に悪い, 悪い手, テキスト, エラー, 指がない, 余分な桁, 桁が少ない, 切り抜き, 標準品質,署名, 透かし, ユーザー名, ぼやけている, 複数の足, 複数の手, 正しくない手足と股間, シュールレアリズム未満, 融合, 長い体, 遠近感が悪い, ロゴ
上記のネガティブプロンプトを設定することで、指が6本になったり手足のバランスが悪くなったりするのを抑え、よりクリアで自然な画像を生成できます。
Stable Diffusionの利用にGoogle Colabを使う理由
Stable DiffusionでAI漫画を作る場合、Google colabの活用が最適です。Stable Diffusionは自身のパソコンへダウンロードして利用できますが、高性能なグラフィックボードやCPUなどが求められます。
しかしGoogle Colabのクラウドベースの開発環境には、ユーザーが使用できるグラフィック処理ユニット(GPU)が備えられています。
Google colabでStable Diffusionを使用する場合、利用できるデータ容量を約1179円から購入可能。高額なPCやグラフィックボードを購入せず利用できるのがメリットです。
Stable Diffusionでオリジナルのキャラクターを作るする方法
今回はGoogle colabを使ってStable Diffusionでオリジナルキャラクターを作る方法について解説します。その際、Google colabでStable Diffusionが使えるようにGPUのリソースを購入しなければなりません。
もし購入していない場合、下記の記事を参考に環境構築からはじめることがおすすめです。

Google Colabでリソースの購入が完了したら、下記のコードを入力して実行します。
【実行コード1】
import os
# Stable Diffusion Web UIのリポジトリが存在しない場合、リポジトリをクローン
repo_path = '/content/stable-diffusion-webui'
if not os.path.exists(repo_path):
!git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui {repo_path}
else:
print("リポジトリはすでに存在します。クローンをスキップします。")
# ダウンロードするモデルの情報を指定
model_files = {
"Animagine-XL-V3.safetensors": {
"url": "https://huggingface.co/cagliostrolab/animagine-xl-3.0/resolve/main/animagine-xl-3.0.safetensors?download=true",
"save_path": os.path.join(repo_path, "models/Stable-diffusion/")
}
}
# モデルが存在しない場合、ダウンロードを実行
for model_name, model_info in model_files.items():
destination = os.path.join(model_info["save_path"], model_name)
if not os.path.exists(destination):
!wget {model_info["url"]} -O {destination}
else:
print(f"{model_name} はすでに存在します。ダウンロードをスキップします。")
上記のコードを実行したあと、下記のコードを入力して実行します。
【実行コード2】
# リポジトリディレクトリに移動
%cd /content/stable-diffusion-webui
# Web UIを起動し、共有リンクを生成して外部アクセスを許可
!python launch.py --share --enable-insecure-extension-access
上記のコードでは視覚的にわかりやすいUIで利用できる「Stable Diffusion Web UI」と、漫画に関するデータを学習している「Animagine XL」というモデルをインストールしています。

Google Colabより
上記のようなリンクが表示されるのでクリックしてください。

Google Colabより
すると上記のようにStable Diffusionの操作画面が表示されます。画面左上にモデルの選択欄があるので、そちらをクリックして「Animagine XL」を選択してください。
次に、作りたい画像のプロンプトとネガティブプロンプトを入力します。実際に使用したプロンプトは下記の通りです。
プロンプト
masterpiece, best quality, monochrome, lineart, 1girl, solo, 20 years old, flat chest, short hair, black hair, hair between eyes, black eyes, long-sleeves, white hoodie, long pants, blue jeans, open eyes, open mouth, standing, cowboy shot, from front, looking at viewer, white background, simple background
ネガティブプロンプト
Worst Quality, Low Quality, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, normal quality,signature, watermark, username, blurry, multiple legs, multiple hands, incorrect limb and crotch, less than surrealism, fused fusion, long body, bad perspective, logo
上記の内容を実行することで下記の画像が生成されました。

Stable Diffusionより
今回は上記のように前髪がセンターとサイドに分かれており、パーカーを着ている女性キャラクターを元に複数のポーズをいくつか作ってみます。
考えている画像を作るプロンプト
masterpiece, best quality, monochrome, lineart, 1girl, solo, 20 years old, flat chest, short hair, black hair, hair between eyes, black eyes, thinking, long-sleeves, white hoodie, crossed arms, long pants, blue jeans, open eyes, close mouth, standing, cowboy shot, from front, looking at viewer, white background, simple background
実行結果

Stable Diffusionより
上記のように被写体が変わらない状態でポーズのみ変更できています。プロンプトに追加・変更した内容は下記の通りです。
追記された要素
- thinking(考えている)
- crossed arms(腕を組んでいる)
変更された要素
open mouth → close mouth(口を開いている → 口を閉じている)
上記のように目や腕、口などを具体的に指定し、考えているポーズをより具体的に伝えるのがコツです。
思いついた画像のプロンプト
masterpiece, best quality, monochrome, lineart, 1girl, solo, 20 years old, flat chest, short hair, black hair, hair between eyes, black eyes, thinking, long-sleeves, white hoodie, long pants, blue jeans, open eyes, open mouth, pointing upward, raised index finger, from waist up, neutral background, simple background, inspired expression
実行結果

Stable Diffusionより
追記された要素
- thinking(考えている)
- pointing upward(上を指している)
- raised index finger(人差し指を上げている)
- from waist up(腰から上の構図)
- neutral background(ニュートラルな背景)
- inspired expression(ひらめいた表情)
変更された要素
- cowboy shot → from waist up(カウボーイショット → 腰から上の構図)
- standing → removed(立っている → 削除)
- looking at viewer → removed(カメラを見ている → 削除)
このように被写体を固定しながら、漫画に必要なシーンを複数作ることが可能です。
次週は漫画を作る際のコマ割りについて詳しく解説します。
※上記コンテンツの内容やソースコードはAIで確認・デバッグしておりますが、間違いやエラー、脆弱性などがある場合は、コメントよりご報告いただけますと幸いです。
ITやプログラミングに関するコラム
 パソコンのキーボード操作一覧表【Windows編】
パソコンのキーボード操作一覧表【Windows編】 FeloとCanvaが連携!数分で高品質プレゼンを作成・編集可能に。具体的な使い方を詳しく解説
FeloとCanvaが連携!数分で高品質プレゼンを作成・編集可能に。具体的な使い方を詳しく解説 テキストを音声化できるスマホアプリ「Reader by ElevenLabs」を使ってみた。
テキストを音声化できるスマホアプリ「Reader by ElevenLabs」を使ってみた。 ポータブルAIボイスレコーダー「PLAUD NotePin」の評判は?具体的な機能やPLAUD Noteとの違い
ポータブルAIボイスレコーダー「PLAUD NotePin」の評判は?具体的な機能やPLAUD Noteとの違い 停滞する日本経済とIT後進国の現実。IT技術の理解から始まるAI活用の可能性
停滞する日本経済とIT後進国の現実。IT技術の理解から始まるAI活用の可能性